(TL;DR)
Prompting is crucial in harnessing the power of LLMs.
This writeup goes through the workflow & some approaches such as Few-Shot Prompting & Chain of Thought Prompting, along with a brief overview on various strategies used in Prompt Engineering.
Table of contents
Open Table of contents
Prompting Workflows
The prompting of a LLM can be compartmentalised into three main blocks as shown below.

Illustration created by me.
Filling Up a Prompt Template
In a template, there are usually three main roles which are concatenated together to generate a token string that is passed to the model for computation.
- System: Message provided to the ‘system’ to influence behavior (i.e. output). This role ensures that this input is hidden from the ‘user’ & the model is protected from injection attacks.
- User: Message inputted by the ‘user’.
- Assistant: Message outputted by the ‘system’.

Image taken from CMU's 11-711 ANLP course.
Here is an example of how the token string that is sent to a model looks like.
Answer Generation & Post-Processing
For the output, you can;
- Use the output as is.
- Format it for better visualization (e.g. format output in markdown tables).
- Extracting parts of the text you want (e.g. “It was simply fantastic”, extract the word “fantastic” for sentiment analysis).
- Mapping it to other actions (e.g. assign the word “fantastic” a positive sentiment during its analysis).
There are various methods for extraction:
- Classification: Identify keywords.
- Regression/numerical problems: Identify numbers.
- Code: Pull out code snippets in triple-backticks.
A key rule of thumb is to use identifiers that occur frequently in the dataset that the model was trained on (e.g. using the scale of “Very Good - Bad” instead of “1 - 5”).
Few-Shot Prompting
This is done by providing a few examples of the task together with the initial instruction. In contrast, Zero-Shot Prompting is the same but no examples are provided. Below is an example of such a prompt.

Image taken from CMU's 11-711 ANLP course.
Some studies have show that the model’s accuracy is sensitive to;
- Ordering of examples.
- Number of positive examples.
- Example coverage (i.e. covers all the possible scenarios).
- Number of examples.
Chain of Thought Prompting
This is done by getting the model to explain its reasoning before making an answer. By doing this the model is able to;
- Decompose the problem.
- Provides addtional computational time.
Below is an example of such a prompt.

Image taken from CMU's 11-711 ANLP course.
It was found that simply adding the text “Let’s think step by step” led to a noticeable increase in accuracy.
Structuring Output as Programs
This is done by getting the model to output its answer in a programming language such as Python or format its response .json. This improves accuracy as;
- Programming languages are natively structured and included in pre-training data (occurs frequently in the dataset).
- Ouputting in JSON, which is a highly popular program output can help with formatting problems.
Below is an example of such a prompt.

Image taken from CMU's 11-711 ANLP course.
Such an approach is especially useful for numeric questions.
Prompt Engineering
There are two main ways in designing prompts;
- Manual: Create a prompt that follows the format of a trained model & tweak it to maximise accuracy (e.g. addition of ’:’ or spacing of text).
- Automated Search: Search in discrete & continuous space.
Manual
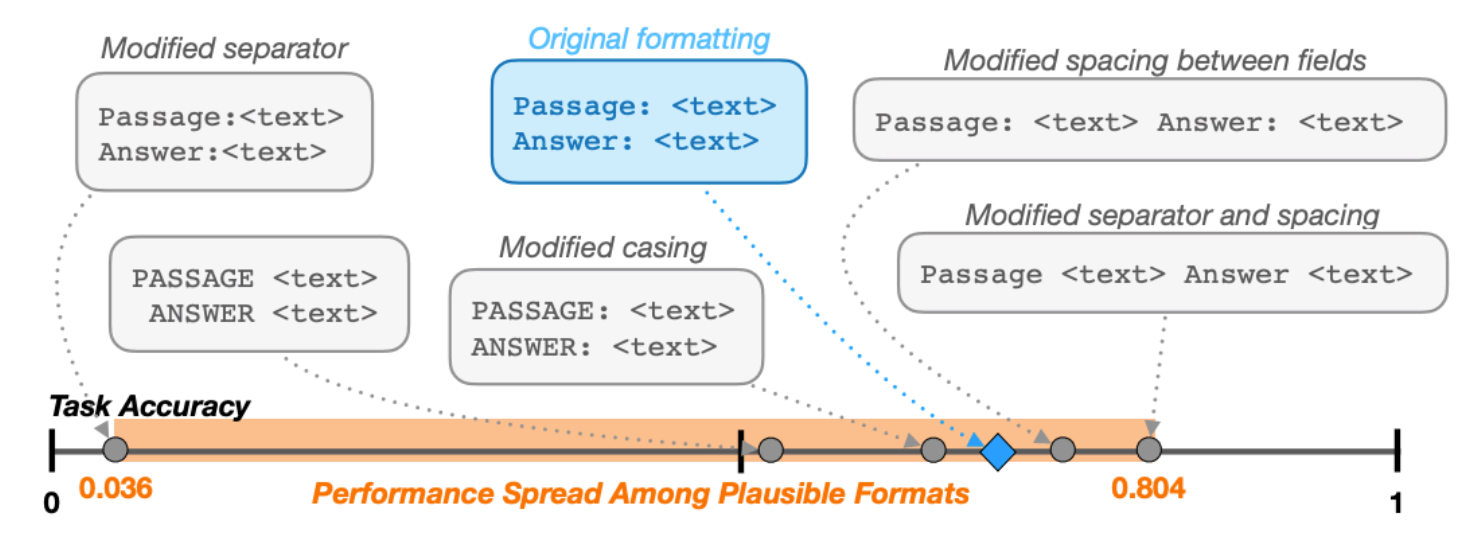
Image taken from CMU's 11-711 ANLP course.
By removing ’:’ and the ‘\n’ in the prompt led to an increase in accuracy.
Automated

Image taken from CMU's 11-711 ANLP course.
By using a Paraphrasing Model to iteratively test other candidates, an optimal prompt can be created.
Conclusion
In summary, prompting is a crucial aspect in the use of large language models.
As these models continue to become more powerful, it then becomes equally important to utilise these techniques to harness the full potential of this tool.